जब आप Snowflake या Databricks को Perplexity से कनेक्ट करते हैं, तो Computer आपके डेटा वेयरहाउस या लेकहाउस का एक Data Map तैयार करता है। Data Map आपके डेटा मॉडल के बारे में महत्वपूर्ण जानकारी कैप्चर करता है — महत्वपूर्ण टेबल और कॉलम, सामान्य क्वेरी पैटर्न, मेट्रिक्स की परिभाषाएँ, और जॉइन के संबंध।
इसे अपने डेटा परिवेश के एक मानचित्र की तरह समझें जो Computer को यह समझने में मदद करता है कि क्या कहाँ है और इसका सामान्य उपयोग कैसे होता है। जनरेट होने के बाद, यह Data Scientist एजेंट के सभी प्रश्नों को सूचित करता है।
यह कैसे काम करता है
Data Map जनरेशन शुरू होने के बाद, Computer आपके कनेक्टेड अकाउंट की अनुमतियों का उपयोग करते हुए आपके डेटा मॉडल का अन्वेषण करता है। यह प्रक्रिया स्कीमा, क्वेरी इतिहास, और एक्सेस पैटर्न की जाँच करती है ताकि यह समझा जा सके कि कौन सी टेबल महत्वपूर्ण हैं और उनका उपयोग कैसे होता है।
Data Map प्रति-संगठन, संस्करणित (versioned) रिपॉज़िटरी में सुरक्षित रूप से संग्रहीत किया जाता है, जो केवल आपके संगठन के सदस्यों के लिए सुलभ है। हर बदलाव — मूल जनरेशन, मैन्युअल एडिट, और स्वीकृत स्व-शिक्षण अपडेट — पूर्ण ऑडिट इतिहास के साथ ट्रैक किया जाता है।
Data Map जनरेट करना
प्रति संगठन एक Data Map होता है, जिसे उस संगठन का हर सदस्य साझा करता है। जब कोई एडमिन जनरेशन चलाता है, तो यह पूरे संगठन की ओर से होता है, न कि किसी एकल उपयोगकर्ता के लिए।
Snowflake
Snowflake के लिए Data Map जनरेशन Snowflake कनेक्टर सेटिंग्स से एक संगठन एडमिन द्वारा शुरू किया जाता है। Perplexity दो Snowflake कनेक्टर शिप करता है, और जनरेशन के लिए उपयोग की जाने वाली पहचान कनेक्टर पर निर्भर करती है:
-
Snowflake (key-pair या PAT) — क्वेरी कॉन्फ़िगर किए गए सर्विस अकाउंट के रूप में चलती हैं।
-
Snowflake (User OAuth) — क्वेरी उस एडमिन की Snowflake पहचान के अंतर्गत चलती हैं जो जनरेशन शुरू करता है।
जो भी पहचान उपयोग की जाती है, वह Snowflake के account-usage views को पढ़ने में सक्षम होनी चाहिए (नीचे Requirements देखें)। यदि वे ग्रांट नहीं हैं, तो जनरेशन शुरुआत में ही एक स्पष्ट permissions error के साथ विफल हो जाएगा, बजाय इसके कि एक आंशिक Data Map तैयार करे।
Databricks
Databricks के लिए, जनरेशन कनेक्टर सेटिंग्स से शुरू किया जाता है और इसमें इनिशिएटर की Databricks OAuth पहचान का उपयोग होता है। Computer उन कैटलॉग, स्कीमा, और टेबल की गणना करता है जिन्हें वह उपयोगकर्ता Unity Catalog में देख सकता है।
पूरक संदर्भ (Snowflake और Databricks)
आप Supplementary context जोड़ सकते हैं — फ़ाइलें अपलोड करें या नोट्स जोड़ें जो आपके डेटा का वर्णन करते हैं (उदाहरण के लिए, मुख्य टेबल किस चीज़ का प्रतिनिधित्व करती हैं, व्यावसायिक परिभाषाएँ, सामान्य क्वेरी पैटर्न) — ताकि Computer आपके संगठन के संदर्भ को बेहतर ढंग से समझ सके। यह पुनर्जनन से प्रभावित नहीं होता, इसलिए आप समय के साथ इसे जोड़ते रह सकते हैं बिना इसके खो जाने की चिंता किए।
View Knowledge
जनरेशन पूरा होने के बाद, कनेक्टर मॉडल पर Generate data map बटन बदलकर View knowledge हो जाता है। View knowledge पर क्लिक करने से Data Map Editor खुलता है, जहाँ एडमिन वह सब कुछ ब्राउज़, एडिट और मैनेज कर सकते हैं जो Computer ने आपके डेटा के बारे में सीखा है। Regenerate data map भी कनेक्टर मॉडल से उपलब्ध होता है जब एक प्रारंभिक Data Map मौजूद हो — यह क्या करता है और क्या संरक्षित रहता है, इसके लिए Regenerating the Data Map देखें।
इसमें कितना समय लगता है?
एक Data Map जनरेट करने में 90 मिनट तक लग सकते हैं, यह आपके डेटा वेयरहाउस या लेकहाउस के आकार और जटिलता पर निर्भर करता है। आपको पेज खुला रखने की आवश्यकता नहीं है — प्रक्रिया बैकग्राउंड में चलती है, और पूरा होने पर कनेक्टर मॉडल पर View knowledge बटन दिखाई देगा।
Data Map एडिटर
Data Map Editor आपके Data Map का एडमिन-फेसिंग व्यू है, जो संगठन एडमिन टूल्स से सुलभ है। यह Snowflake और Databricks Data Map को अलग-अलग दिखाता है ताकि आप प्रत्येक वेयरहाउस को स्वतंत्र रूप से प्रबंधित कर सकें।
एडिटर से, एडमिन ये कर सकते हैं:
-
Browse पूरे Data Map को — व्यावसायिक संदर्भ, टेबल क्लस्टर, सामान्य क्वेरी पैटर्न।
-
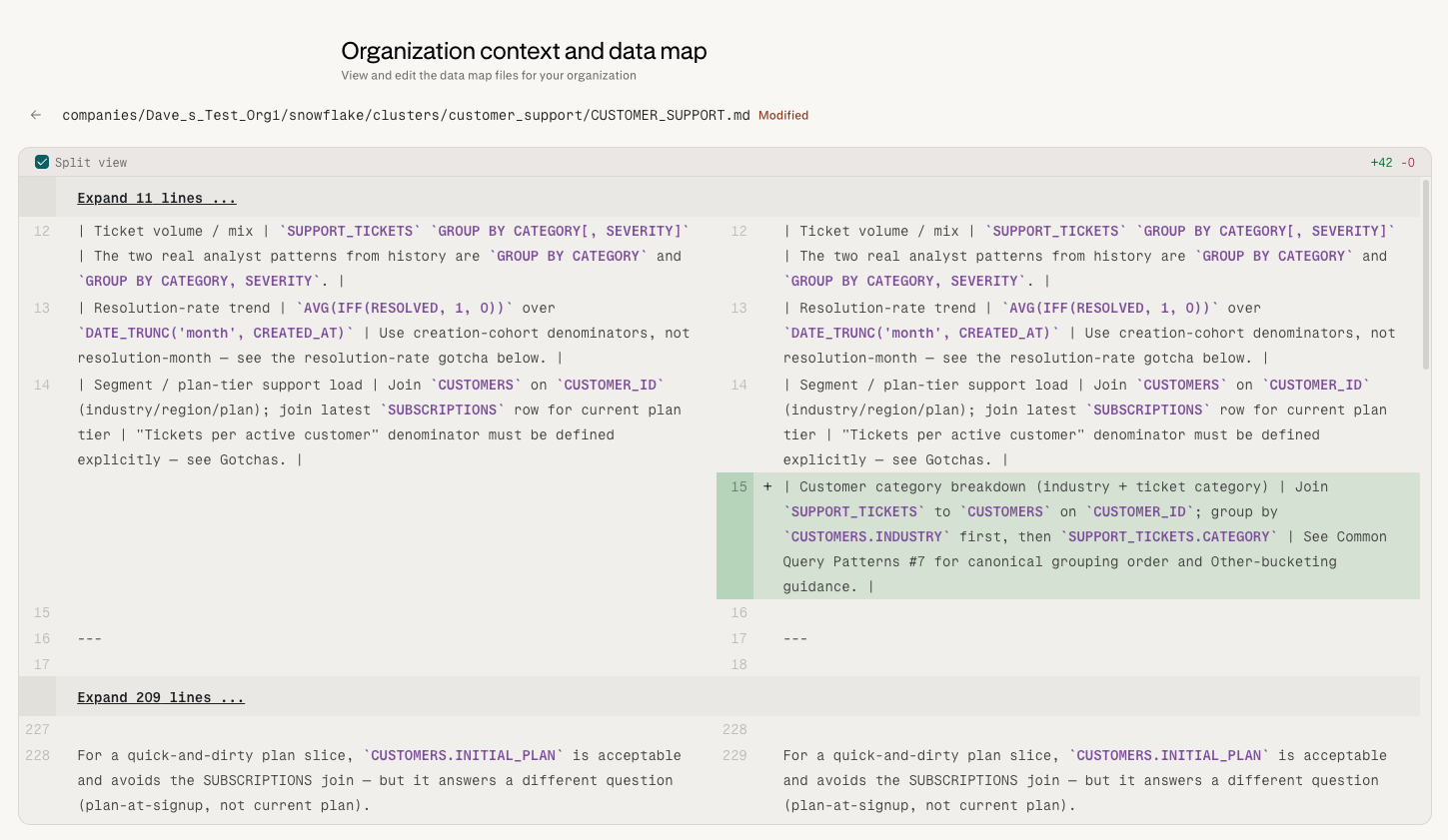
Edit फ़ाइलों को सीधे। सहेजे गए एडिट तुरंत लाइव Data Map पर लागू हो जाते हैं और नया ग्राउंड ट्रुथ बन जाते हैं; उन्हें स्व-शिक्षण समीक्षा प्रक्रिया से गुज़रने की आवश्यकता नहीं होती।
-
AI-प्रस्तावित बदलावों की समीक्षा और कार्रवाई स्व-शिक्षण पाइपलाइन से। एडमिन प्रस्ताव को approve कर सकते हैं (बदलाव Data Map पर लागू होते हैं) या reject कर सकते हैं (प्रस्ताव त्याग दिया जाता है)। अनुमोदन से पहले प्रस्ताव को मौके पर संशोधित करना आज समर्थित नहीं है — जो एडमिन एक अलग परिणाम चाहते हैं, उन्हें प्रस्ताव को अस्वीकार करना चाहिए और मैन्युअल रूप से एडिट करना चाहिए।
-
संस्करण इतिहास देखें किसी भी फ़ाइल का, और आवश्यकता होने पर वापस रोलबैक करें।
एडिटर में किए गए सीधे एडिट सामान्य उपयोग के लिए टिकाऊ होते हैं, लेकिन वे ऑटो-जनरेट की गई सामग्री के साथ रहते हैं और यदि आप उस वेयरहाउस के लिए Data Map को पुनर्जनन करते हैं तो वे संरक्षित नहीं रहते — नीचे Regenerating the Data Map देखें।
फ़ीडबैक से स्व-शिक्षण
जितना अधिक आपकी टीम Data Map का उपयोग करती है, उतना ही यह बेहतर होता जाता है। जब कोई उपयोगकर्ता किसी सेशंस में डेटा एजेंट को सही करता है — उदाहरण के लिए, "क्वेरी काउंट के लिए fct_queries का उपयोग करें, query_events का नहीं" या "क्वेरी वॉल्यूम मेट्रिक्स से type = 'internal' को बाहर रखें" — तो Computer उस फ़ीडबैक को कैप्चर करता है और सभी के लिए Data Map को बेहतर बनाने के लिए उपयोग करता है।
पाइपलाइन को safe, reviewable, और पूरे संगठन में साझा होने के लिए डिज़ाइन किया गया है:
1. फ़ीडबैक कैप्चर करना
जब कोई उपयोगकर्ता Data Scientist सेशंस में फ़ीडबैक देता है, तो Computer एक संरचित सुधार लॉग करता है — वह फ़ाइल जिसे प्रभावित करना चाहिए, अनुभाग, पिछला मान, और नया मान। यह तुरंत Data Map को नहीं बदलता; इसे समेकन (compaction) के लिए लाइन में लगाया जाता है।
2. प्रस्तावित अपडेट में दैनिक समेकन
दिन में एक बार, Computer प्रत्येक संगठन के लिए पिछले 24 घंटों में लॉग किए गए सुधारों की समीक्षा करता है और Data Map के लिए एक एकल समेकित प्रस्तावित अपडेट तैयार करता है:
-
एक ही क्षेत्र में कई सुधारों को एक एडिट में merged कर दिया जाता है।
-
परस्पर विरोधी सुधार (उदाहरण के लिए, एक कहता है "हमेशा cron jobs शामिल करें," दूसरा कहता है "हमेशा cron jobs को बाहर रखें") को स्वतः-हल करने के बजाय मानवीय समीक्षा के लिए अलग रखा जाता है।
-
प्रत्येक सुधार को सही वेयरहाउस पर रूट किया जाता है — एक Snowflake-विशिष्ट सुधार Databricks Data Map में नहीं घुसेगा और न ही इसके विपरीत।
-
जिन सुधारों को आत्मविश्वास के साथ मर्ज या रूट नहीं किया जा सकता, उन्हें चुपचाप लागू करने के बजाय एडमिन की समीक्षा के लिए फ़्लैग किया जाता है।
परिणाम Data Map Editor में एक एकल प्रस्ताव के रूप में सामने आता है जिसकी एडमिन समीक्षा कर सकते हैं।
3. एडमिन समीक्षा
एडमिन प्रस्ताव को approve कर सकते हैं (बदलाव Data Map पर लागू होते हैं) या reject कर सकते हैं (प्रस्ताव त्याग दिया जाता है)। अनुमोदन ही वह क्रिया है जो बदलावों को "deploy" करती है — अगला डेटा प्रश्न जो आपकी टीम पूछेगी, वह अपडेट किए गए Data Map का उपयोग करेगा। यदि कोई एडमिन कई दिनों तक समीक्षा नहीं करता है, तो अप्रकाशित प्रस्ताव लंबित रहते हैं — वे अपने आप लागू नहीं होते।
यह human-in-the-loop पैटर्न जानबूझकर बनाया गया है: यह Computer को वास्तविक उपयोग से लगातार सीखने देता है, जबकि एडमिन इस पर नियंत्रण रखते हैं कि क्या ग्राउंड ट्रुथ के रूप में विश्वसनीय माना जाए।
कौन क्या कर सकता है?
-
कोई भी उपयोगकर्ता Data Scientist सेशंस में फ़ीडबैक दे सकता है, जो अगले दिन के प्रस्तावित अपडेट में योगदान करता है।
-
संगठन एडमिन Data Map फ़ाइलों को सीधे ब्राउज़ और एडिट कर सकते हैं, और Data Map Editor में दैनिक प्रस्तावित अपडेट को स्वीकृत या अस्वीकृत कर सकते हैं।
-
प्रति संगठन एक Data Map होता है — संगठन का हर सदस्य उसी साझा Data Map के विरुद्ध क्वेरी करता है। प्रति-उपयोगकर्ता कोई Data Map नहीं होता।
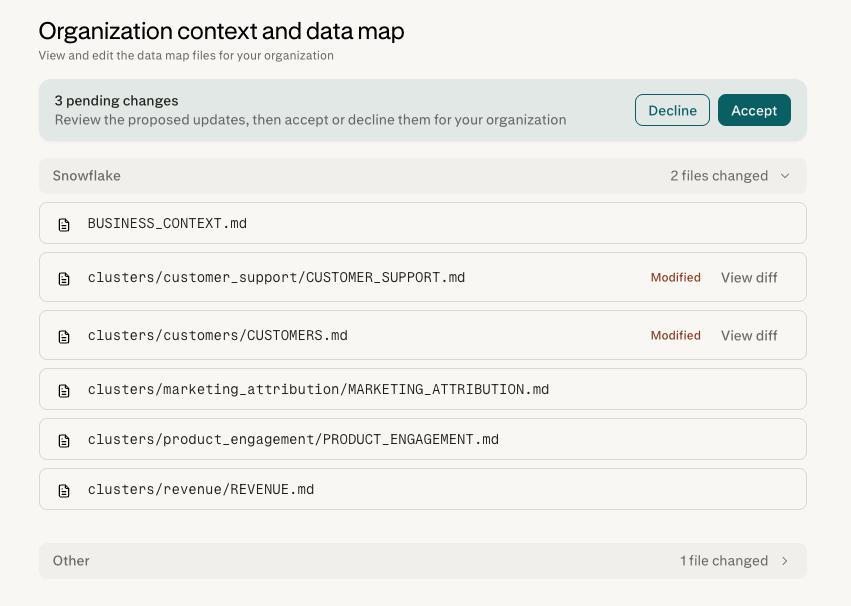
Data Map का पुनर्जनन
एडमिन कनेक्टर मॉडल से किसी भी समय Regenerate Data Map चला सकते हैं। आज, पुनर्जनन का अर्थ है जिस वेयरहाउस को आप पुनर्जनन कर रहे हैं, उसके लिए शून्य से एक पूर्ण पुनर्निर्माण:
-
उस वेयरहाउस का Data Map पूरी तरह से एक नए परिणाम से बदल दिया जाता है। उस वेयरहाउस के Data Map पर किए गए मैन्युअल एडमिन एडिट संरक्षित नहीं रहते।
-
अन्य दूसरे वेयरहाउस का Data Map अछूता रहता है — Snowflake का पुनर्जनन Databricks को प्रभावित नहीं करता, और न ही इसके विपरीत।
-
Supplementary context संरक्षित रहता है और नए रन पर फिर से लागू होता है।
-
लंबित फ़ीडबैक (उस दिन लॉग किए गए सुधार जो अभी तक प्रस्तावित अपडेट में नहीं समेटे गए हैं) संरक्षित रहता है। जो फ़ीडबैक पहले से स्वीकृत होकर Data Map पर लागू हो चुका है, वह नए परिणाम का हिस्सा बन जाता है।
-
पूरा संस्करण इतिहास संरक्षित रहता है, इसलिए Data Map के पुराने संस्करण निरीक्षण योग्य बने रहते हैं।
चूँकि पुनर्जनन एक वेयरहाउस के Data Map और उसमें किए गए किसी भी एडमिन एडिट को बदल देता है, इसलिए इसे जानबूझकर चलाया जाना चाहिए। एक सुरक्षित पुनर्जनन जो एडमिन एडिट को संरक्षित रखता है — और एक अलग स्पष्ट "पूर्ण रीसेट" — रोडमैप पर हैं लेकिन आज प्रोडक्ट में नहीं हैं।
आवश्यकताएँ
Snowflake
Data Map जनरेट करने के लिए उपयोग की गई पहचान — key-pair / PAT auth के लिए सर्विस अकाउंट, या OAuth auth के लिए शुरू करने वाले एडमिन का Snowflake user — के पास निम्नलिखित को पढ़ने की अनुमति होनी चाहिए:SNOWFLAKE.ACCOUNT_USAGE स्कीमा:
-
SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY -
SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY(Snowflake Enterprise Edition या उच्चतर)
महत्वपूर्ण: ACCOUNT_USAGE डिफ़ॉल्ट रूप से केवल एडमिन के लिए सुलभ है। जनरेशन विफल होने का सबसे सामान्य कारण ऐसी भूमिका है जो आपके नियमित डेटाबेस पढ़ सकती है लेकिन ACCOUNT_USAGE तक उसकी पहुँच नहीं है। इसका समाधान है IMPORTED PRIVILEGES को SNOWFLAKE डेटाबेस पर ग्रांट करना।
यदि आपने प्रारंभिक सेटअप के दौरान यह एक्सेस पहले से ग्रांट नहीं किया है, तो निम्नलिखित को ACCOUNTADMIN के रूप में चलाएँ:
GRANT IMPORTED PRIVILEGES ON DATABASE SNOWFLAKE TO ROLE <your_role>;
फिर कनेक्ट करने वाली भूमिका से सत्यापित करें:
SELECT 1 FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY LIMIT 1; SELECT 1 FROM SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY LIMIT 1;
यदि ACCESS_HISTORY उपलब्ध नहीं है (Snowflake Standard Edition), तो जनरेशन केवल QUERY_HISTORY पर वापस आ जाता है। Data Map फिर भी काम करेगा, लेकिन कॉलम लीनिएज और टेबल-एक्सेस गणना पर थोड़ा कम सटीक सिग्नल के साथ।
पूर्ण सेटअप निर्देशों के लिए, Connecting Perplexity with Snowflake देखें।
Databricks
Databricks जनरेशन इनिशिएटर की OAuth पहचान का उपयोग करता है और उसकी Unity Catalog अनुमतियों को विरासत में लेता है — किसी अतिरिक्त ग्रांट की आवश्यकता नहीं है। ध्यान देने योग्य कुछ व्यावहारिक बातें:
-
Unity Catalog आवश्यक है। Computer क्वेरी इतिहास के लिए Databricks सिस्टम टेबल पढ़ता है, जो Unity Catalog पर निर्भर हैं। केवल
hive_metastoreपर चलने वाले Workspaces जनरेशन के दौरान एक्सेस जाँच में विफल हो जाएँगे। -
एक SQL warehouse चालू होना चाहिए जब जनरेशन शुरू किया जाए। यदि कोई वेयरहाउस नहीं चल रहा है, तो पहले Databricks में एक शुरू करें।
-
इनिशिएटर जो भी Unity Catalog में देख सकता है, वही परिभाषित करता है कि Data Map में क्या आएगा। यदि कोई कैटलॉग या स्कीमा उस उपयोगकर्ता से छिपा हुआ है, तो Computer उसे शामिल नहीं कर सकता।
पूर्ण सेटअप निर्देशों के लिए, Connecting Perplexity with Databricks देखें।