Snowflake または Databricks を Perplexity に接続すると、Computer はデータウェアハウスまたはレイクハウスのデータマップを生成します。データマップは、Computer が自然言語の質問を正確なクエリに変換できるよう、データモデルに関する重要な情報(重要なテーブルとカラム、一般的なクエリパターン、オブジェクト間の関係)を取得します。
これはデータ環境のマップとして機能し、Computer がどこに何があり、通常どのように使用されているかを理解するのに役立ちます。一度生成されると、データマップは継続的に改善されます。ユーザーフィードバックから学習し、管理者が直接編集でき、変更は常にレビューおよびロールバックできるようにバージョン管理されます。
仕組み
データマップの生成が開始されると、Computer は接続されたアカウントの権限を使用してデータモデルを調査します。このプロセスではスキーマ、テーブル、ビュー、過去の使用パターンを検証して、データの包括的な理解を構築します。
データマップは、組織ごとのバージョン管理されたリポジトリに安全に保存され、組織のメンバーのみがアクセスできます。
データマップの生成
データマップは 組織につき1つで、その組織のすべてのメンバーが共有します。管理者が生成を実行する際は、個人ではなく組織全体の代表として行います。
Snowflake
Snowflake のデータマップ生成は、Snowflake コネクターの設定から組織管理者が開始します。Perplexity には 2 つの Snowflake コネクターがあり、管理者は組織が設定したコネクターからデータマップを生成します:
-
Snowflake (キーペアまたは PAT)— クエリは設定されたサービスアカウントとして実行されます。
-
Snowflake(ユーザー OAuth) — クエリは生成を開始した管理者の Snowflake ID で実行されます。
使用される ID は、Snowflake のアカウント使用状況ビューを読み取れる必要があります( 要件 を参照)。これらの権限が不足している場合、生成は部分的なデータマップを生成するのではなく、明確な権限エラーで最初から失敗します。
Databricks
Databricks の場合、生成はコネクター設定から開始者の Databricks OAuth ID を使用して開始されます。Computer は Unity Catalog でそのユーザーが見ることができるカタログ、スキーマ、テーブルを列挙し、使用シグナルのために Databricks システムテーブルを読み取ります。開始者が Unity Catalog で見ることができるものが、データマップに含まれる内容を定義します。
補足コンテキスト(Snowflake および Databricks)
補足コンテキストを追加できます。これはデータを説明するファイルのアップロードやメモの追加です(例:重要なテーブルが表すもの、ビジネス定義、一般的なクエリパターン)。補足コンテキストは生成後にコネクターモーダルから 補足コンテキスト — ファイルのアップロードやメモの追加でデータを説明できます(例:重要なテーブルが表すもの、ビジネス定義、一般的なクエリパターン)— Computer がデータをより正確に解釈できるようになります。 Supplementary context is fed into every generation run and is 再生成によって影響を受けません。そのため、時間をかけて追加し続けても、失う心配はありません。
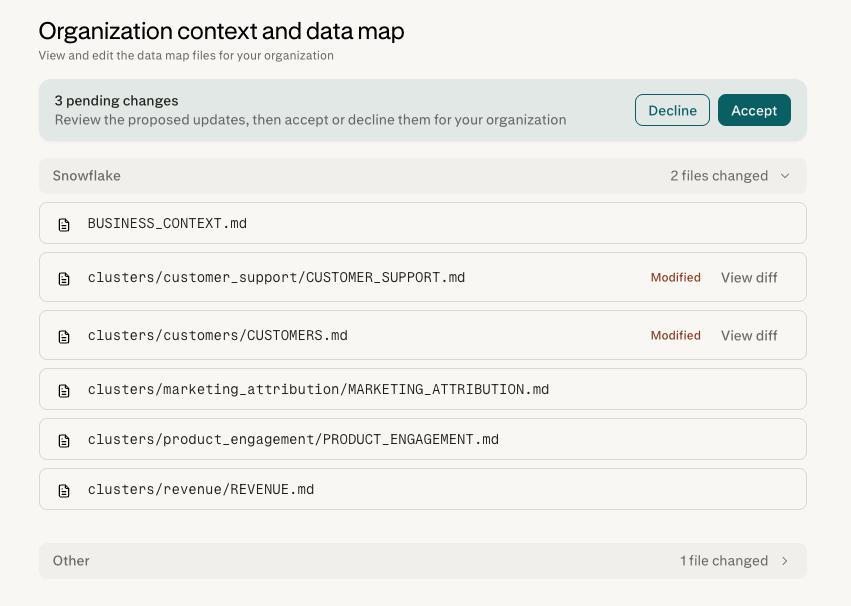
ナレッジの表示
生成が完了すると、コネクターモーダルの データマップを生成 ボタンが ナレッジを表示に変わります。 ナレッジを表示 をクリックすると、 データマップエディターが開き、管理者は Computer がデータについて学んだすべてのコンテンツを閲覧、編集、管理できます。 データマップを再生成 は、初期データマップが作成された後にコネクターモーダルから使用できます — see データマップの再生成 の説明と保持されるものについてご覧ください。
どのくらい時間がかかりますか?
データマップの生成には 最大90分かかる場合があります(データウェアハウスまたはレイクハウスのサイズと複雑さによって異なります)。ページを開いたままにしておく必要はありません。プロセスはバックグラウンドで実行され、 ナレッジを表示 ボタンが完了後にコネクターモーダルに表示されます。
データマップエディター
データマップエディターは管理者向けのデータマップビューで、組織管理者ツールからアクセスできます。Snowflake と Databricks のナレッジを個別のセクションに分離し、基礎となるビジネスコンテキスト、テーブルクラスター、クエリパターンは直接読み書きできるファイルとして整理されています。
エディターから管理者は以下の操作が可能です:
-
閲覧 (データマップ全体:ビジネスコンテキスト、テーブルクラスター、一般的なクエリパターン)
-
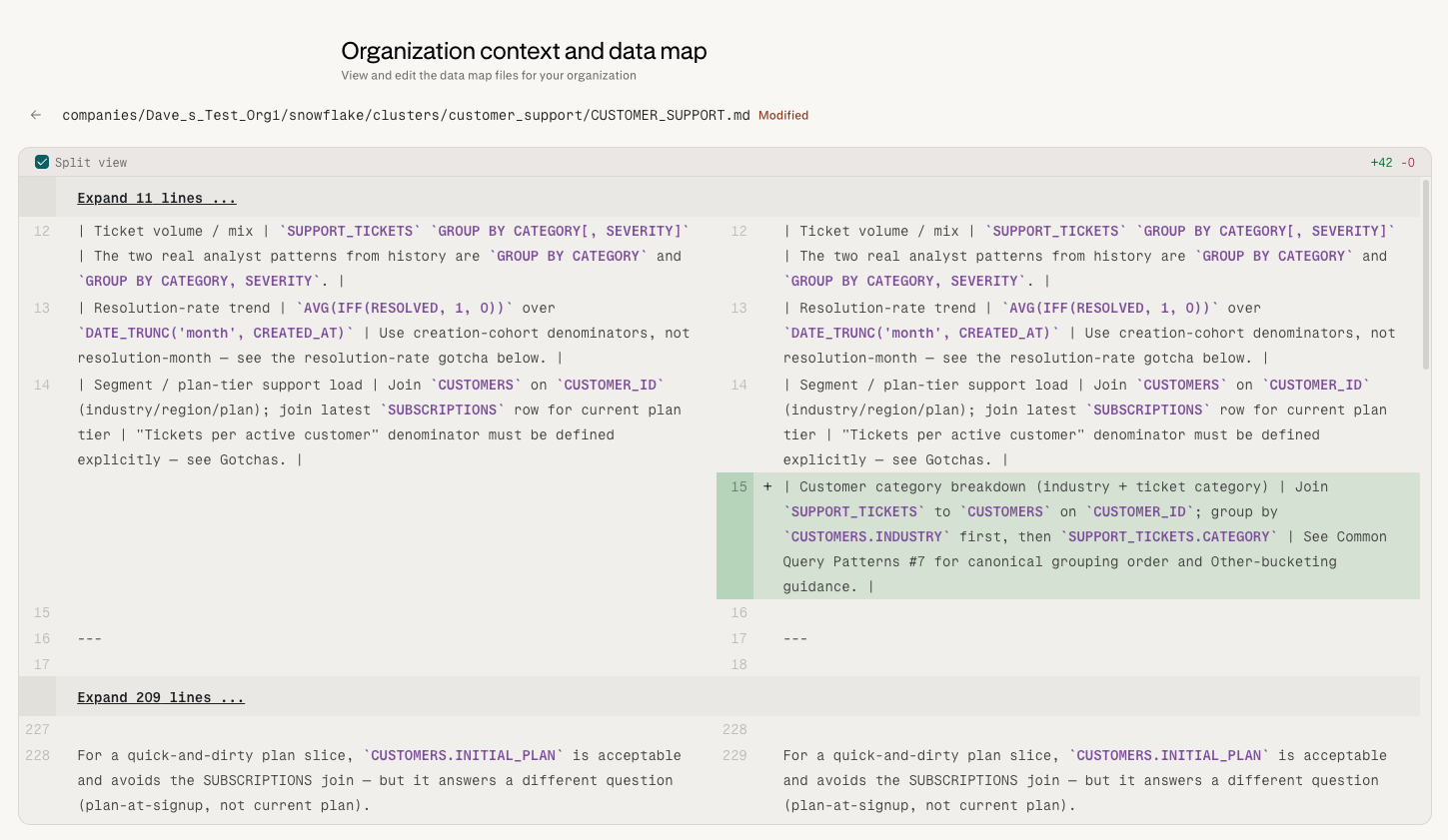
編集 (ファイルを直接編集。保存された編集は即座にライブデータマップに適用され、新しいグラウンドトゥルースになります。レビューパイプラインを経る必要はありません)
-
AI が提案した変更のレビューと対応 (自己学習パイプラインからの変更。管理者は 承認 (変更がデータマップに適用)または 却下 (提案が破棄されます)。承認前に提案をその場で修正する機能は現在サポートされていません — 別の結果を望む管理者は、却下した後に自分で編集を行うことができます。
-
バージョン履歴を表示 して、必要に応じてロールバックできます。
エディターでの直接編集は通常使用では永続的ですが、自動生成されたコンテンツと共存しており、 そのウェアハウスのデータマップを再生成すると保持されません — see データマップの再生成 below.
フィードバックからの自己学習
チームが使うほど、データマップは改善されます。ユーザーがセッション内でデータエージェントを修正すると(例:「クエリカウントには query_events の代わりに fct_queries を使用してください」または「クエリボリュームメトリクスから type = 'internal' を除外してください」)、Computer はそのフィードバックを記録してデータマップの改善に使用します。
パイプラインは safe, reviewable、および 組織全体で共有される:
1. フィードバックの収集
ユーザーが Data Scientist セッションでフィードバックを提供すると、Computer はフィールド、期待される値と実際の値のロジック、コンテキストなどの構造化された修正を記録し、今後の応答を改善します。
2. 提案された更新への日次コンパクション
1日に1回、Computer は各組織の過去24時間に記録された修正を確認し、単一の統合された proposed update をデータマップに:
-
同じ領域への複数の修正は1つの編集にまとめられます。
-
矛盾する修正 (例:一方が「常に cron ジョブを含める」、もう一方が「常に cron ジョブを除外する」と言う場合)は 人間によるレビューのために保留 自動解決されるのではなく。
-
各修正は適切なウェアハウスにルーティングされます — Snowflake 固有の修正が Databricks のデータマップに影響することはなく、その逆も同様です。
-
自信を持ってマージまたはルーティングできない修正は、サイレントに適用されるのではなく、管理者が確認するためにフラグが立てられます。
結果は管理者がレビューできる単一の提案としてデータマップエディターに表示されます。
3. 管理者レビュー
管理者 承認 (変更がデータマップに適用)または 却下 (提案が破棄されます)。承認が変更を「デプロイ」します — チームが次にデータに関する質問をすると、更新されたデータマップが使用されます。別途公開ステップはありません。
この人間参加型パターンは意図的なものです。Computer がリアルな使用から継続的に学習しながら、管理者がグラウンドトゥルースとして信頼されるものを制御し続けられるようにします。
誰が何をできるか?
-
すべてのユーザー データサイエンティストスレッドでフィードバックを提供でき、翌日の提案された更新に反映されます。
-
Org admins データマップファイルを直接参照および編集でき、データマップエディターで日次の提案された更新を承認または却下できます。
-
データマップは 組織につき1つ — 組織の全メンバーが同じ共有データマップに対してクエリを実行します。ユーザーごとのデータマップはありません。
データマップの再生成
管理者は実行できます データマップを再生成 コネクターモーダルからいつでも実行できます。現在、再生成は 再生成するウェアハウスの最初からの再構築:
-
そのウェアハウスのデータマップは新しい結果で完全に置き換えられます。 そのウェアハウスのデータマップへの手動の管理者編集は保持されません。
-
もう一方のウェアハウスのデータマップはそのまま維持されます — Snowflake を再生成しても Databricks のデータマップには影響せず、その逆も同様です。
-
補足コンテキスト が保持され、新しい実行に再適用されます。
-
保留中のフィードバック (その日に記録されたがまだ提案された更新にまとめられていない修正)は保持されます。すでに承認されてデータマップに適用されたフィードバックは、置き換えられる部分に含まれます。
-
完全なバージョン履歴は保持されるため、データマップの以前のバージョンは引き続き検査できます。
再生成はウェアハウスのデータマップとその管理者編集を置き換えるため、意図的に実行する必要があります。 管理者編集を保持するより安全な再生成と、別途の明示的な「完全リセット」については、ロードマップに含まれていますが、現在はまだ提供されていません。
要件
Snowflake
データマップの生成に使用されるアイデンティティ(キーペア/PAT 認証の場合はサービスアカウント、OAuth 認証の場合は開始管理者の Snowflake ユーザー)は、SNOWFLAKE.ACCOUNT_USAGE スキーマの次の2つのビューを読み取れる必要があります:
-
SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY -
SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY(Snowflake Enterprise Edition 以上)
重要: ACCOUNT_USAGE はデフォルトで管理者専用です。生成が失敗する最も一般的な原因は、通常のデータベースを読み取ることはできるが、 ACCOUNT_USAGEにアクセスできないロールです。修正方法は IMPORTED PRIVILEGES on the SNOWFLAKE database.
初期セットアップ時にこのアクセスをまだ付与していない場合は、次のコマンドを ACCOUNTADMIN:
GRANT IMPORTED PRIVILEGES ON DATABASE SNOWFLAKE TO ROLE <your_role>;
次に、接続ロールから確認します:
SELECT 1 FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY LIMIT 1; SELECT 1 FROM SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY LIMIT 1;
If ACCESS_HISTORY が利用できない場合(Snowflake Standard Edition)、生成は QUERY_HISTORY のみにフォールバックします。データマップは引き続き機能しますが、列の系譜とテーブルアクセスカウントに関するシグナルの精度がやや低下します。
完全なセットアップ手順については、以下をご覧ください: Perplexity と Snowflake の接続.
Databricks
Databricks の生成では、開始者の OAuth アイデンティティが使用され、Unity Catalog の権限が継承されます。追加の権限付与は不要です。知っておくべき実用的な注意点がいくつかあります:
-
Unity Catalog が必要です。 Computer はクエリ履歴の Databricks システムテーブルを読み取ります(Unity Catalog に依存)。以下のみで動作するワークスペース:
hive_metastoreは生成中のアクセスチェックに失敗します。 -
A SQL ウェアハウスが実行中である必要があります 生成が開始されるとき。ウェアハウスが実行されていない場合は、最初に Databricks でウェアハウスを起動してください。
-
開始者が Unity Catalog で見ることができるものが、データマップに含まれる内容を定義します。カタログまたはスキーマがそのユーザーから隠されている場合、Computer はそれを含めることができません。
完全なセットアップ手順については、以下をご覧ください: Perplexity と Databricks の接続.